
When testing an hypothesis with a categorical explanatory variable and a quantitative response variable, the tool normally used in statistics is Analysis of Variances, also called ANOVA.
In this post I am performing an ANOVA test using the R programming language, to a dataset of breast cancer new cases across continents.
The objective of the ANOVA test is to analyse if there is a (statistically) significant difference in breast cancer, between different continents. In other words, I am interested to see whether new episodes of breast cancer are more likely to take place in some regions rather than others.
Beyond analysing this specific breast cancer dataset, I hope with this post to create a short tutorial about ANOVA and how to do simple linear models in R.
Sometimes ago I took a statistics course and this was actually part of the assignment; I hope there won't be major errors in the methodology I am going to follow, and of course any feedback/critique will be very welcome.
The Dataset
My dataset has breast cancer data for 173 countries as it was originally collected by ARC (International Agency for Research on Cancer) in 2002. The dataset also includes several other socio-economic variables about countries, though I am not gonna explore them in this occasion. To obtain the final dataset, I conducted some minor cleaning and added the "continent" variable, through a merge operation. To see how I've done this, you can also check a previous post about merging datasets with R.
If you like to get the final dataset, you can download it here in .csv format. Once imported into R, I stored it into a variable called "gapCleaned".
Define the ANOVA model mathematically
As already mentioned above, I am going to examine the relationship between:
- Continents, which is my explanatory variable --> let’s call it X
- and New Cases of Breast Cancer, which is my response variable --> let’s call it Y
Mathematically, the relationship can be written like this:
Y ~ X
ANOVA is going to compare means of breast cancer among the seven continents, and check if differences are statistically significant. Here are my null and alternative hypothesis:
- Null Hypothesis: all seven continents means are equal —> there is no relationship between continents and new cases of breast cancer, which we can write as follows:
- Alternative Hypothesis: not all seven continents means are equal —> there is a relationship between continents and new cases of breast cancer:
Perform the ANOVA test with R
So, how do we go about testing the means? First of all we can calculate and plot means for each continent, which is pretty easy to do with R (remember, my breast cancer dataset is called "gapCleaned in R):
> means<- round(tapply(gapCleaned$breastcancer, gapCleaned$continent, mean), digits=2) # note that I I round values to just 2 decimal places
> means
AF AS EE LATAM NORAM OC WE
24.02 24.51 49.44 36.70 71.73 45.80 74.80
> library(gplots) #I load the "gplots" package to plot means
> plotmeans(gapCleaned$breastcancer~gapCleaned$continent, digits=2, ccol=”red”, mean.labels=T, main=”Plot of breast cancer means by continent”)
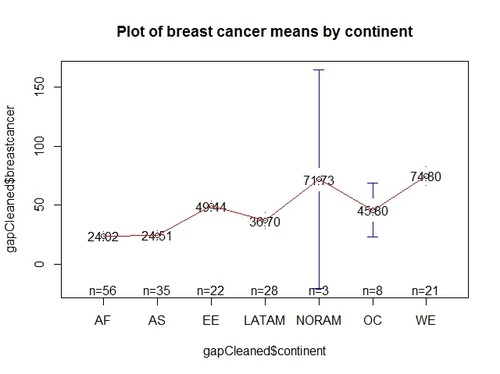
The above graph shows how breast cancer means change between continents, as well as the number of countries taken into account for calculating the mean of each continent. Cool, it looks like means differ among continents, with Africa presenting the lowest value and West Europe the highest. But… hang on, is that enough to provide evidence against my null hypothesis? Not really and we can understand why, through a lovely boxplot:
> boxplot(gapCleaned$breastcancer ~ gapCleaned$continent, main=”Breast cancer by continent (mean is black dot)”, xlab=”continents”, ylab=”new cases per 100,00 residents”, col=rainbow(7))
> points(means, col=”black”, pch=18)
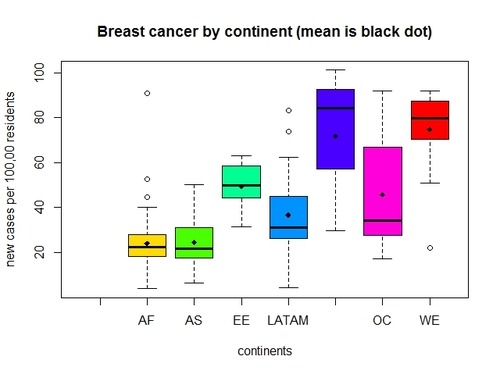
(* the blue boxplot with missing label, refers to North America).
The boxplot shows that means are different (some less, others more). But it also shows that each continent present a different amount of variation/spread in breast cancer, so that there is much overlap of values between some continents (e.g. Africa&Asia or North America & West Europe). Hence, differences in means could have come about by chance (and we shouldn’t reject the null hypothesis case). That is where ANOVA comes to help us.
The question we are answering with ANOVA is: are the variations between the continents means due to true differences about the populations means or just due to sampling variability? To answer this question, ANOVA calculates a parameter called F statistics, which compares the variation among sample means (among different continents in our case) to the variation within groups (within continents).
F statistics = Variation among sample means / Variation within groups
Through the F statistics we can see if the variation among sample means dominates over the variation within groups, or not. In the first case we will have strong evidence against the null hypothesis (means are all equals), while in the second case we would have little evidence against the null hypothesis.
All right, after this theoretical excursus, it’s time to perform ANOVA on my data and try to interpret results. To call ANOVA with R, I am using the “aov” function:
> aov_cont<- aov(gapCleaned$breastcancer ~ gapCleaned$continent)
> summary(aov_cont) # here I see results for my ANOVA test
Df Sum Sq Mean Sq F value Pr(>F)
gapCleaned$continent 6 52531 8755 40.28 <2e-16 ***
Residuals 166 36083 217
—————
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Good, my F value is 40.28, and p-value is very low too. In other words, the variation of breast cancer means among different continents (numerator) is much larger than the variation of breast cancer within each continents, and our p-value is less than 0.05 (as suggested by normal scientific standard). Hence we can conclude that for our confidence interval we accept the alternative hypothesis H1 that there is a significant relationship between continents and breast cancer.
But we are not done yet… :(
What I know at this point (thanks to ANOVA), is that NOT ALL THE MEANS ARE EQUAL. However my categorical variable “continents” has more than two levels (actually it has 7), and it might be that it’s just one continent that is not equal to the others. ANOVA doesn’t tell me which groups (continents) are different from the others. In this sense we will have to see each pair of continents to appreciate significant differences.
To determine which groups are different from the others I need to conduct a POST HOC TEST or a post hoc pair comparison (note we can’t perform multiple anova tests one for each pair, as this would increase our error, see family wise error rate for more details) which is designed to evaluate pair means. There are many post hoc tests available for analysis of variance and in my case I will use the Tukey post hoc test, calling with R the function “TukeyHSD” as follows:
> tuk<- TukeyHSD(aov_cont)
> tuk
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = gapCleaned$breastcancer ~ gapCleaned$continent)
$`gapCleaned$continent`
diff lwr upr p adj
AS-AF 0.4953571 -8.986848 9.9775626 0.9999987
EE-AF 25.4248377 14.352007 36.4976680 0.0000000
LATAM-AF 12.6875000 2.501977 22.8730225 0.0050172
NORAM-AF 47.7172619 21.638434 73.7960896 0.0000035
OC-AF 21.7839286 5.151040 38.4168172 0.0025337
WE-AF 50.7886905 39.528172 62.0492093 0.0000000
EE-AS 24.9294805 12.956321 36.9026399 0.0000001
LATAM-AS 12.1921429 1.034462 23.3498237 0.0223712
NORAM-AS 47.2219048 20.748253 73.6955563 0.0000067
OC-AS 21.2885714 4.043225 38.5339174 0.0056343
WE-AS 50.2933333 38.146389 62.4402777 0.0000000
LATAM-EE -12.7373377 -25.274849 -0.1998261 0.0437993
NORAM-EE 22.2924242 -4.791696 49.3765447 0.1822328
OC-EE -3.6409091 -21.809489 14.5276712 0.9967979
WE-EE 25.3638528 11.938369 38.7893364 0.0000015
NORAM-LATAM 35.0297619 8.296134 61.7633901 0.0025162
OC-LATAM 9.0964286 -8.545414 26.7382711 0.7208506
WE-LATAM 38.1011905 25.397612 50.8047690 0.0000000
OC-NORAM -25.9333333 -55.725866 3.8591991 0.1332198
WE-NORAM 3.0714286 -24.089965 30.2328219 0.9998787
WE-OC 29.0047619 10.721189 47.2883344 0.0000943
Results & Interpretations
From the table above (looking at “diff” and “p adj” columns) I can see which continents have significant differences in breast cancer from others. For example I can conclude that:
- there is no significant difference in breast cancer new cases between Asia and Africa ( p =0.99 > 0.05), as well as between West Europe and North America (p=0.99) or Oceania and Latin America (p=0.72), etc.
- THERE IS A SIGNIFICANT DIFFERENCE in breast cancer new cases between East Europe and Africa (p= 0.00) as well as between Latin America and Africa (p=0.005) or West Europe and Oceania (p=0.00)
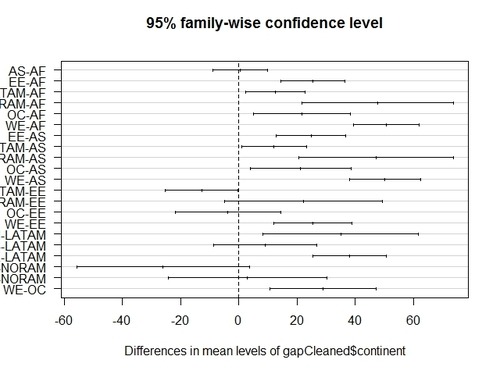
Finally, I can also visualize continent pairs and analyse significant differences by plotting the the “tuk” object in R (sorry the y axis is not displayed properly). Significant differences are the ones which not cross the zero value.
> plot (tuk)
Conclusions
Despite the interesting findings obtained from the ANOVA test, which show a potential relationship between some continents/countries (most developed ones in particular) and breast cancer incidence, I am not going to draw any concrete conclusion from the data. This because the model I've built (Y~X) misses considering some potential confounding variables such as for example:
- access to health care and breast cancer screenings: Africa and Asia might have many women with breat cancer, but they might be undiagnosed due to lack of access to diagnostic and treatment services. On the other hand, it looks like there are more women in developed countries with breast cancer, but it may just be because these countries offer a better access to health services;
- life expectancy: age at diagnosis is another variable to take into consideration, since life expectancy is far lower in less developed countries like Africa and Asia. Age is an important component in breast cancer causes (women over 50 are more likely to get breast cancer), and it might be that because of higher life expectancy, most developed countries present more cases than less developed ones.
While it is impossible with such a "poor" model to draw concrete results from my data analysis, I guess we should take this post as a "learning exercise" that shows the main steps for performing an ANOVA test with R, and the logic behind it. I hope you found it helpful and please add your own considerations, critiques, comments below.
Other R articles you will find useful:
Global Distribution of Breast Cancer: some initial considerations
Plotting Data over a Map with R
My first R Shiny Web Application using Breast Cancer Data
Other R articles you will find useful:
Global Distribution of Breast Cancer: some initial considerations
Plotting Data over a Map with R
My first R Shiny Web Application using Breast Cancer Data
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.